True high availability
Cloud hosting, 100% up-time, server high availability… These words have become very popular and attractive. And then it’s you, who needs hosting for a valuable project, solution for millions and your income source. There’s no doubt you want your page be online. Always. Keep reading…
A bit of history
In the old, really old days we did only had physical servers, which often looked like desktop machines, boosted with a bit of extra memory and components, which normally costs double in a shop. When such computer would hang – every task, that was running on it would stop. Website, mail, database.. At this point you would be calling your hosting company, asking them – what’s wrong-when will it be up and running again.. Luckily those days we had much less traffic and people would understand it. Today everything has changed – the Internet has grown a lot and in most cases, if page is not available – you’ll find another within a couple of minutes. Being up all the time has become critical for most online projects.
Luckily hardware has changed as well. Server virtualization nowadays is not considered as anything special anymore. New technologies brought administrators new tools for keeping servers up and running. Resources now are being spread across several physical machines, they are being duplicated, fault-tolerance is a new term, that is often being put in question when selecting hosting provider. This has lowered downtime a lot. But it has not excluded it, I’m afraid.
True high availability explained
What can bring website, hosted on a modern platform today? Several factors:
- datacenter internet connection problems (DDOS, technical maintenantce);
- bad server configuration or server overload;
- routing problems to datacenter (rare, but still).
What would we call true high availability then? Take a look at the following scheme:
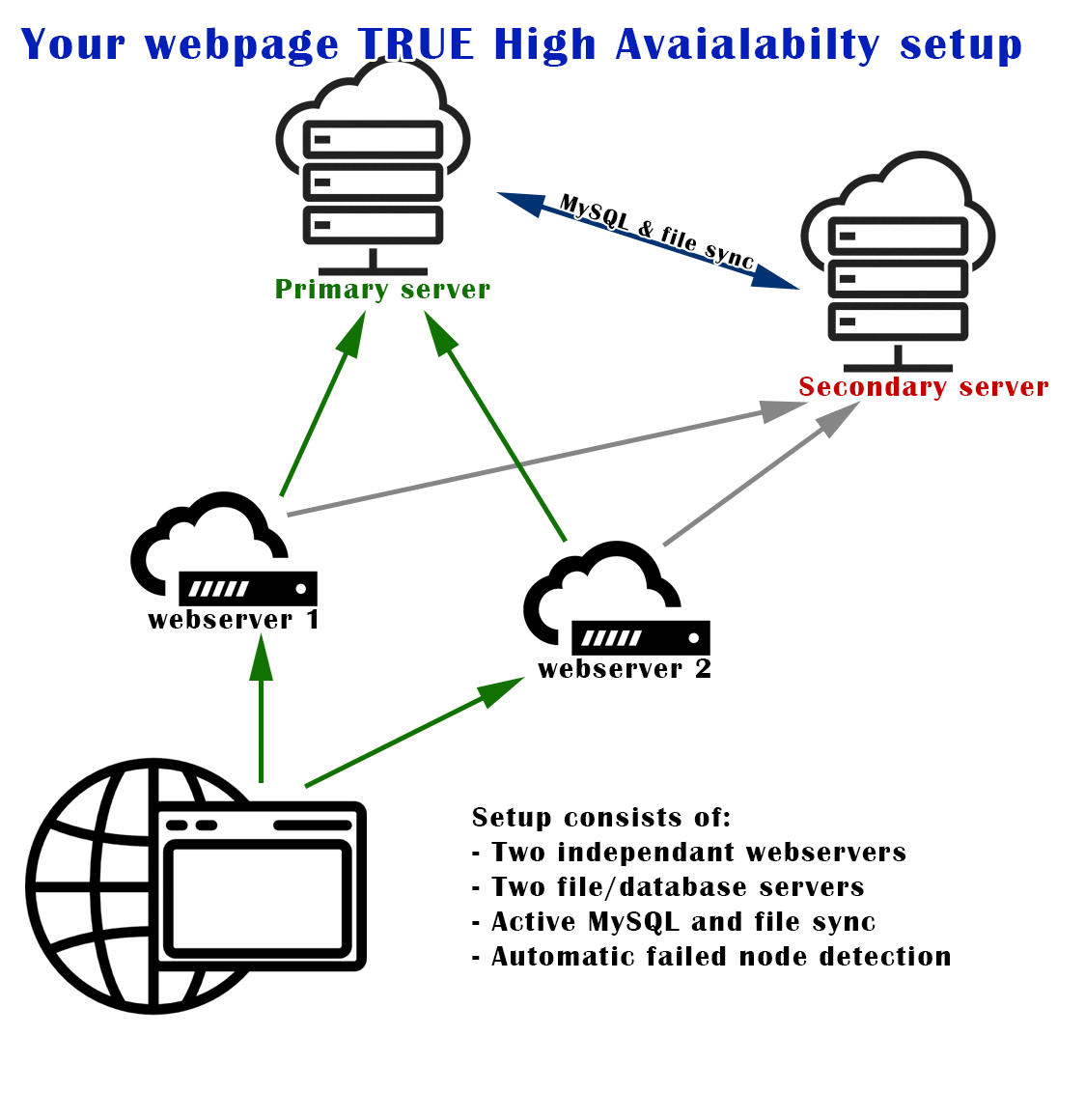
True high availability for modern hosting is 2 totally independent locations with active and not dependent on each other file and database sync. This must not include any virtualization software sync, both servers must be independent and provide content, let new data publishing on any of them and streamline switch, if any of them fails. Also there should be at least 2 independent webservers or reverse proxy servers, which would be responsible for both load balancing and failed node detection. They must be located independently. With this setup there might be 2 failed nodes and still webpage would run and be active with no interaction from you side. Fully automatically.
Yes. This sounds very good. If you are interested in such solution for your project, please contact us for more details.